正则表达式匹配网页标签之间任意字符
<div id=”textbody” class=”content”>
<div class=”desinfo”><div class=”intro”> 我们以前曾经解释过404错误页面产生的原因,一旦访客进入404页面,他们很可能不知道下一步该做什么。他们正在搜索的页面也许已被转移,所以你应该尽可能地帮助他们找到它,或是他们查找的页面可能已被删除,这意味着他们很可能会离开你的网站,除非你可以激</div></div>
<div class=”content”>
<p> 我们以前曾经解释过404错误页面产生的原因,一旦访客进入404页面,他们很可能不知道下一步该做什么。他们正在搜索的页面也许已被转移,所以你应该尽可能地帮助他们找到它,或是他们查找的页面可能已被删除,这意味着他们很可能会离开你的网站,除非你可以激励他们留下来。 <br style=”background-color:#f6f6f4;padding:0px;margin:0px;” /><br style=”background-color:#f6f6f4;padding:0px;margin:0px;” />你可以做很多事情来改进你的错误页面,我们列出了以下一些具有创造性和启发性的建议: <br style=”background-color:#f6f6f4;padding:0px;margin:0px;” /></p>
<p align=”center”> </p>
</div>
</div>
<div class=”pagebreak”>
使用的是正则表达式在线测试工具,http://tool.chinaz.com/regex/
最终获取结果如下:
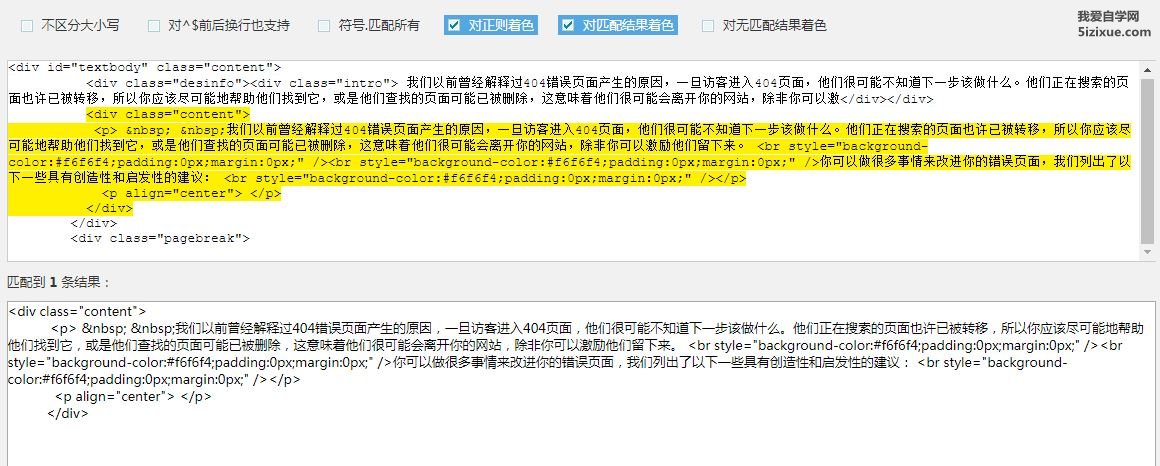
开始写的正则是<div class=”content”>(.*),写到这里时发现无法获得换行之后的文本。于是查了一下手册,才发现正则表达式中,“.”(点符号)匹配的是除了换行符“\n”以外的所有字符。同时,手册上还有一句话:要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式。于是我将正则表达式的匹配规则修改如下:
<div class=”content”>[.\n]*,写完后发现还是无法获得换行后的文本。
上网查了一番,找到了正确的匹配表达式,以下为正确的正则表达式匹配规则:
<div class=”content”>[\s\S]*</p>\s*</div>
同时,也可以用 “([\d\D]*)”、“([\w\W]*)” 来表示。
在文本文件里, 这个表达式可以匹配所有的英文
/[ -~]/
这个表达式可以匹配所有的非英文(比如中文)
/[^ -~]/
/是VI里用的. 你在editplus或程序里不需要/
